Graph Traversal — Breadth-First Search vs Depth-First Search (Pt 1)
As I continue in my software engineering journey, the importance of understanding algorithms is becoming more and more relevant. Employers want to know that you don’t just memorize code, but you understand the fundamentals of best coding practices.
Graph traversal is a common scenario you will encounter when dealing with large groups of data. A graph is a non-linear data structure that contains nodes and edges. A node(aka vertex) is a single unique value in a graph, while an edge represents a relationship between these two nodes.

Think of a social media app. A user is a node and when a user follows another user that creates an edge (relationship) between the two nodes. Now think of how large an app like Facebook or Twitter is and just imagine how massive a graph that creates! This highlights the importance of graphs and being able to properly traverse them.
Well… graphs and their relationships can be confusing at times, how can we visualize them?
Adjacency Matrix:
The adjacency matrix is essentially a table that represents the amount of edges there are between two nodes. As we can see below, A to A has no edges because A does not connect to itself, B to A does however have a connection so we put a 1 in the column, the same goes for C to A and so on.

This is a great way to visualize a small graph like the one I have above, but in a larger graph, we may see a lot more zeroes than we do ones, which takes up loads of space for no reason. For scenarios like that, we will use an Adjacency list.
Adjacency List:
the adjacency list reduces blank spaces and directly identifies which nodes connect with one another. As I said before, this is often times a better way to visualize a graph and its edges without having so much blank space.

In the image above, we have our adjacency list to the left. This list represents connections between nodes. A connects to both B and C, B connects to A, and so on.
Now we’ve got a solid, fundamental understanding of graphs, but how do we properly traverse them? What if we want to know if node A eventually connects to node D without this visual representations? In comes the algorithms!!
Breadth-First Search:
Breadth-First Search (or BFS for short) is a graph traversal strategy that searches a graph one level at a time, heres a visual example:

From the starting node (layer 0), we add all of the direct children (layer 1) to a queue. Once those nodes have been visited, move on to the next set of children (layer 2) and so on. Something to note is that it is important to mark which nodes have been visited, as you don’t want to visit the same node twice.
Another option we have for graph traversal is the Depth-First Search.
Depth-First Search:
This graph traversal strategy is a recursive algorithm that involves backtracking. In this scenario backtracking means that you move forward (node by node) until there are no more nodes to visit. If there are no more nodes to visit, the algorithm will go back one node, and see if there is a another path to follow. If there is a path to follow, it follows that path until there are no nodes left to search, thus repeating the cycle.
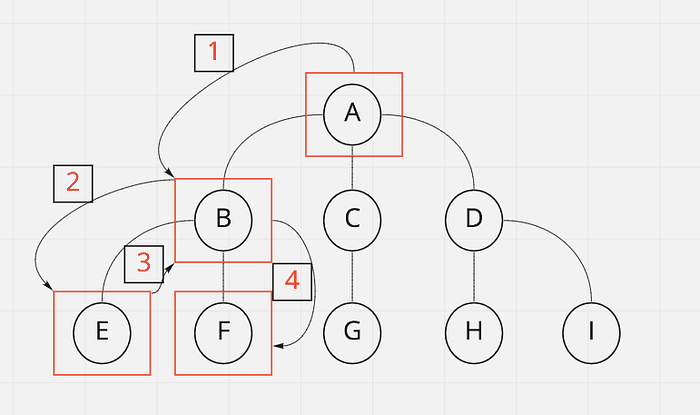
This may look a little confusing, but I will explain! Above we have the same graph we traversed using the breadth-first search algorithm, only this time, we’re using the depth-first search algorithm.
Step 1: Starting from the top(A) we visit the first child node(B)
Step 2: Now at B, we move on to B’s first child node(E)
Step 3: If E does not meet the criteria we are looking for, and since there are no more child nodes below it, ultimately we have to go back to the parent node(B) to check if it has any other children.
Step 4: B does have another child(F)! So we then visit that node. If that node fits our criteria, then voilà! The algorithm is solved! BUT, if it does not fit our criteria, we go back to the parent(B) and check if it has any more children and so on.
This cycle repeats itself until the node we are searching for is found.
Now you may be wondering, these algorithms are both pretty effective at searching for nodes, which one do I choose?
Picture this, in the example above we first move on to node B, not node C or D, but what if the node we are searching for is node D, a mere child of node A. That means we would be searching node B and all its children, then node C and all its children, then FINALLY move on to node D. That means our algorithm wasted a whole bunch of time searching other sections of the graph when the answer was right in front our faces!
Ultimately, people favor the breadth-first search algorithm over depth-first search for this very reason. I am not saying the DFS should never be used, but it could turn out to be a real time waster.
I hope you found this article useful in learning more about BFS and DFS!
If you want to see me implement DFS and BFS algorithms using JavaScript, check out my second article here!
